Цели мониторинга
Managed Availability framework вырос из опыта мониторинга облачного решения Exchange Online средствами пакета управления для Exchange 2010 в OpsMgr. Опыт использования пакета управления показал, что он избыточен, из более чем тысячи алертов полезными в Exchange Online оказались только 150. Остальные были в итоге отключены.
Из облачного решения так же растёт необходимость мониторинга доступности со стороны конечных потребителей сервиса. С точки зрения потребителя сервис не доступен только тогда, когда он не может его использовать. Остальные случаи ему не интересны. То есть в первую очередь мы должны наблюдать доступность сервиса со стороны клиента. Внутренние поломки, не влияющие на доступность клиентов к сервису менее интересны и не так важны.
Из последнего важное следствие. Все поломки, ведущие к недоступности сервиса для клиента, необходимо исправлять максимально быстро, желательно автоматически, без привлечения операторов системы. Поэтому система мониторинга должна быть направлена на восстановление доступности сервиса и только потом на выяснение причин недоступности.
Поэтому Managed Availability – решение, позволяющее автоматически восстанавливать части системы после сбоев, а не обычная система мониторинга, которая, обычно, завязана на действия оператора. Кроме этого MA тесно интегрировано с механизмом обеспечения высокой доступности Exchange.
Managed Availability измеряет три ключевых аспекта системы – доступность, подключения пользователей (обычно, в виде измерения задержек ответа от сервисов, обеспечивающих клиентские подключения) и возникающие ошибки.
Самое важное отличие от предыдущих систем – Managed Availability не нацелен на выявление ключевой причины сбоя. Основная задача – максимально снизить недоступность сервиса для клиента. То есть получить ответы на следующие вопросы:
- Availability: Может ли пользователь подключиться к сервису?
- Latency: Насколько успешно пользователь работает с сервисом?
- Errors: Способен ли пользователь выполнить те действия, который он хочет выполнить?
Компоненты
Managed Availability состоит из трёх асинхронных компонентов: probe engine (отвечает за измерение различных параметров сервиса), monitor (содержит бизнес логику, которая позволяет на основе измерений от probe engine сделать заключение здоров сервис или нет), responder engine (выполняет восстановление сервиса на основе инструкций, полученных от монитора).
Решение максимально децентрализовано. Решение о здоровье сервиса принимается в рамках конкретного сервера. Восстановление так же происходит в рамках конкретного сервера.
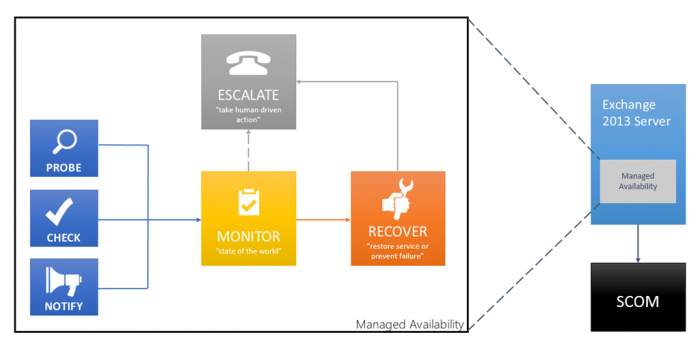
Подробнее по компонентам ниже.
Probes
Инфраструктура состоит из трёх фрэймворков:
- Probes – являются синтетическими транзакциями, которые созданы командами, отвечающими ра различные сервисы в рамках системы Exchange. Измеряют доступность сервиса на основе эмуляции действий пользователя.
- Checks – пассивный механизм мониторинга. В основном измеряет различные метрики производительности.
- Notifications – основан на внешних механизмах мониторинга (например, ServerOneCopyMonitor или мониторинг сертификатов с истёкшим сроком действия). Результаты сразу поступают в монитор и позволяют уведомлять оператора о проблеме.
Все три типа мониторов пишут события в канал Microsoft-Exchange-ActiveMonitoring\ProbeResult в Event Log. Каждый монитор имеет свойство SampleMask, по которому ищет события в этом канале, содержащие те же данные в свойстве ResultName события из канала.
Сбой одной пробы не говорит о сбое сервиса. Бизнес-логика обработки таких сбойных проб прописана в мониторе.
Recurrent Probes
Основной фрэймворк. Пробы запускаются раз в несколько минут и проверяют некоторые аспекты состояния здоровья сервиса. Они могут, например, отправлять письмо в мониторинговый ящик через ActiveSync, проверять подключение MAPI/HTTP или проверять подключение между FrontEnd/BackEnd компонентами. Почти все такие пробы определены в Event Log в канале Microsoft-Exchange-ActiveMonitoring\ProbeDefinition. Интересные свойства:
- Name: имя пробы
- TypeName: код типа пробы, которые содержит логику пробы
- ServiceName: имя набора здоровья для пробы
- TargetResource: объект, который проверяет проба
- RecurrenceIntervalSeconds: как часто запускается проба
- TimeoutSeconds: тамйаут для пробы
Существует два основных типа проб:
– Microsoft.Exchange.Monitoring.ActiveMonitoring.ServiceStatus.Probes.GenericServiceProbe: определяет запущен ли сервис, указанный в TargetResource
– Microsoft.Exchange.Monitoring.ActiveMonitoring.ServiceStatus.Probes.EventLogProbe: записывает в лог ошибку если событие, указанное в ExtensionAttributes.RedEventIds, появляется в ExtensionAttributes.LogName. Успешные результаты записываются в ExtensionAttributes.GreenEventIds. Эти пробы перестанут работать если перенастроить их на поиск других событий.
Повторяющаяся проба запускается согласно интервалу, указанному в RecurrenceIntervalSeconds и проверяет некоторые аспекты определённого компонента сервиса. Если компонент здоров, то в канал Microsoft-Exchange-ActiveMonitoring\ProbeResult записывается информационное событие с кодом 3 в ResultType. Если проверка возвращает ошибку или отваливается по таймауту, то в этот же канал записывается ошибка. Для ошибки указывается 4 в ResultType. Для таймаута указывается 1. Многие пробы будут перезапущены при таймауте столько раз, сколько указано в параметре MaxRetryAttempts конкретной пробы.
Checks
Пробы, которые пишут события в Eventlog в случае, когда определённый счётчик производительности переходит определённый порог или опускается ниже него. Конкретные пороги указываются в следующих свойствах монитора, связанного с пробой:
– Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueAboveThresholdMonitor
– Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueBelowThresholdMonitor
Notifications
Пробы этого типа запускаются вне рамок сервиса Health Manager, другими сервисами. Эти сервисы осуществляют самостоятельный мониторинг и затем отправляют собранные данные напрямую в Managed Availability в результаты пробы. Эти пробы не описываются в канале ProbeDefinition.
Например, монитор ServerOneCopyMonitor срабатывает в результате данных полученных из пробы, которые пишет сервис MSExchangeDagMgmt. Этот сервис осуществляет свой собственный мониторинг, определяет существует ли проблема и логгирует результаты проверки. Большинство проб этого типа умеют записывать информацию о проблеме, так и информацию о том, что проблема ушла. Это позволяет автоматически преводить мониторы из состояния здоров в не здоров и наоборот.
Monitors
Данные собранные предыдущим механизмом передаются в мониторы. Мониторы могут собирать данные с нескольких проб. На основании этих данных монитор принимает решение о состоянии здоровья сервиса или компонента. Решения всего два – здорово и не здоров.
Мониторы могут находиться на разных слоях системы:
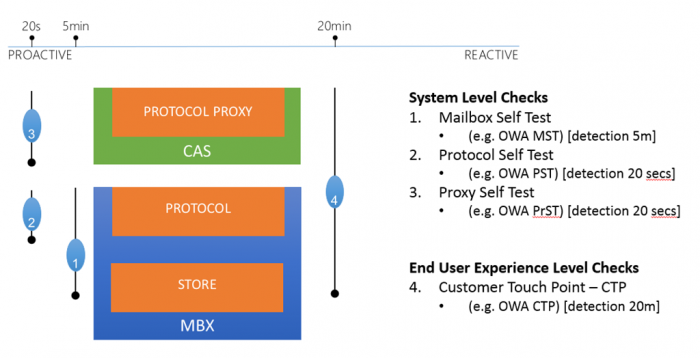
На уровне хранилища, протокола, проксирующего механизма, либо на уровне доступ пользователя к сервису.
Мониторы являются центральными компонентами Managed Availability. Они определяют какие данные нужно собирать, из каких компонентов складывается состояние определённого сервиса и какие действия предпринять, чтобы восстановить в рабочее состояние определённый сервис.
Каждый монитор описывается в канале Microsoft-Exchange-ActiveMonitoring\MonitorDefinition.
Почти все мониторы собирают три типа данных: прямые уведомления, результаты запуска проб и счётчики производительности.
Мониторы, которые изменяют своё состояние на основании прямых уведомлений получают данные только от прямых уведомлений.
Мониторы, получающие данные из проб, разделяются на два типа: основанных на количестве последовательных сбоев проб и основанных на количестве сбоев проб за определённый интервал времени.
Мониторы, получающие данные от счётчиков производительности, просто определяют выше или ниже определённого порога счётчик производительности.
Responders
Респондеры являются критической финальной частью процесса Managed Availability. Респондеры выполняют определённые действия на основе предупреждений от мониторов. Респондеры никогда не начинают работать, пока монитор здоров.
Респондеры описываются в следующем канале – Exchange-ActiveMonitoring/ResponderDefinition. Некоторые важные свойства респондеров:
- TypeName: код действия восстановления респондера.
- Name: имя респондера.
- ServiceName: HealthSet частью которого является респондер.
- TargetResource: объект на котором будет срабатывать респондер.
- AlertMask: монитор для конкретного респондера.
- ThrottlePolicyXml: как часто разрешено запускать респондер.
Результаты выполнения респондеров находятся в канале Microsoft-Exchange-ActiveMonitoring/ResponderResult. Результаты восстановления пишутся в канал Microsoft-Exchange-ManagedAvailability/RecoveryActionResults. Действия респондеров описываются в канале Microsoft-Exchange-ManagedAvailability/RecoveryActionLogs.
Когда запускается респондер происходит проверка ограничений тротлинга для него. Это сопровождается записью событий 2050 (запуск разрешён) или 2051 (запуск запрещён) в канал RecoveryActionLogs. Пример события 2051:
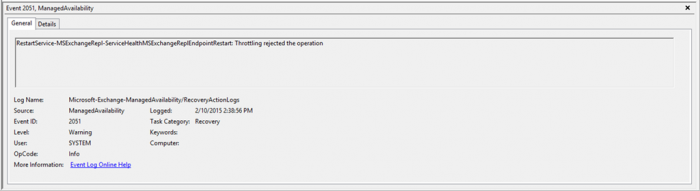
В Details:
| ActionId | RestartService |
| ResourceName | MSExchangeRepl |
| RequesterName | ServiceHealthMSExchangeReplEndpointRestart |
| ExceptionMessage | Active Monitoring Recovery action failed. An operation was rejected during local throttling. (ActionId=RestartService, ResourceName=MSExchangeRepl, Requester=ServiceHealthMSExchangeReplEndpointRestart, FailedChecks=LocalMinimumMinutes, LocalMaxInDay) |
| LocalThrottleResult | <LocalThrottlingResult IsPassed=”false” MinimumMinutes=”60″ TotalInOneHour=”1″ MaxAllowedInOneHour=”-1″ TotalInOneDay=”1″ MaxAllowedInOneDay=”1″ IsThrottlingInProgress=”true” IsRecoveryInProgress=”false” ChecksFailed=”LocalMinimumMinutes, LocalMaxInDay” TimeToRetryAfter=”2015-02-11T14:29:57.9448377-08:00″> <MostRecentEntry Requester=”ServiceHealthMSExchangeReplEndpointRestart” StartTime=”2015-02-10T14:29:55.9920032-08:00″ EndTime=”2015-02-10T14:29:57.9448377-08:00″ State=”Finished” Result=”Succeeded” /> </LocalThrottlingResult> |
| GroupThrottleResult | <not attempted> |
| TotalServersInGroup | 0 |
| TotalServersInCompatibleVersion | 0 |
По первым полям видно, что была осуществлена попытка перезапуска сервиса MSExchangeRepl респондером ServiceHealthMSExchangeReplEndpointRestart. Основная информация находится в параметре LocalThrottleResult. В ChecksFailed указана причина – LocalMinimumMinutes. Респондер уже запускался в течение последнего часа.
Существуют следующие типы респондеров:
- Restart Responder – останаливает и перезапускает сервис
- Reset AppPool Responder – перезапускает пул приложений IIS
- Failover Responder – выводит из использования сервер Exchange
- Bugcheck Responder – запускает bugcheck на сервере
- Offline Responder – выводит из использования конкретный протокол на сервере
- Escalate Responder – эскалирует проблему оператору
- Specialized Component Responders
Оффлайн респондер выводит из использования конкретный протокол. Тут важно понимать, что он никак не связан с балансировщиком нагрузки, если такой используется. Если отрабатывает такой респондер, то балансировщик должен вывести из использования сервер, на котором выводится из использования определённый протокол, но не наоборот.
Эскалирующий респондер генерирует определённое событие в Event log, которое потом отображается в Operations Manager. Важно понимать, что в Operations Manager уходит информация о том, что определённый монитор здоров или не здоров, а не информация, полученная монитором из проб.
Последовательность восстановления
Мониторы определяют типы респондеров и в каком порядке они должны срабатывать. Эти настройка хранятся в параметре StateTransitionXML монитора.
Например, если проба для OWA собирает информацию, на основе которой монитор делает заключение что OWA не здоров, то у нас имеется следующая последовательность респондеров для такого монитора:
- В момент времени T=0 запускается Reset Application Pool респондер
- Если через T=5 минут монитор не становится здоровым запускается Failover респондер, перемещающий активные базы с сервера
- Если через T=8 минут монитор не становится здоровым запускается Bugcheck респондер и сервер перезапускается
- Если через T=15 минут монитор не становится здоровым запускается Escalate респондер
Если на любом шаге монитор становится здоровым, то последовательность респондеров останавливается и состояние монитора немедленно меняется на здоров.
Systems Center Operations Manager (SCOM)
Используется в качестве портала, который отображает информацию о состоянии здоровья системы Exchange. Состояние здоровья формируется на основе событий в EventLog, которые создаются Escalate респондером.
Панель OpsMgr отображает три области:
- Active Alerts
- Organization Health
- Server Health
Overrides
Во многих системах настройки по-умолчанию не являются оптимальными. Для таких систем можно эти настройки переписать. Переписать настройки можно на уровне конкретного сервера и на уровне всей организации. Каждая такая настройка действует определённое время или на определённые версии серверов Exchange.
Для работы с такой кастомизацией используются командлеты *-ServerMonitoringOverride и *-GlobalMonitoringOverride.
Определение здоровья
Мониторы, которые связаны с определённым компонентом архитектуры системы группируются вместе в Health Sets. Здоровье каждого такого набора определяется как худшее состояние его составляющих. То есть, если хотя бы один из мониторов такого набора нездоров, то нездоровым считается весь набор. Health Set монитора указывается в параметре ServiceName монитора.
Определить набор мониторов, связанных с ними проб и респондеров в определённом наборе можно с помощью командлета Get-MonitoringItemIdentity.
Для определения состояния здоровья можно использовать командлеты Get-ServerHealth и Get-HealthReport. Они оперируют на нескольких уровнях:
- Они могут отображать состояние здоровья всего сервера и наборов здоровья для него
- Они могут отображать состояние здоровья конкретного набора и мониторов из которых он состоит
- Они могут отображать суммарное состояние здоровья набора серверов (DAG, например)
Например, определить состояние каждого набора здоровья можно так:
Get-HealthReport –Identity Server1
Результат может быть таким:
Server State HealthSet AlertValue LastTransitionTime MonitorCount ------- ----- ------ ------ ------ ------ Server1 NotApplicable AD Healthy 5/21/2013 12:23 14 Server1 NotApplicable ECP Unhealthy 5/26/2013 15:40 2 Server1 NotApplicable EventAssistants Healthy 5/29/2013 17:51 40 Server1 NotApplicable Monitoring Healthy 5/29/2013 17:21 9 … … … … … …
Видно, что набор ECP в состоянии Unhealthy. Так же по столбцу MonitorCount видно, что состоит он из двух мониторов.
Посмотреть состояние этим мониторов можно так:
Get-ServerHealth –Identity Server1 –HealthSet ECP
Результат будет:
Server State Name TargetResource HealthSetName AlertValue ServerComponent ------ ------ ------ ------ ------ ------ ------ Server1 NotApplicable EacSelfTestMonitor ECP Unhealthy None Server1 NotApplicable EacDeepTestMonitor ECP Unhealthy None
Видно, что оба монитора нездоровы. Дальнейшие действия можно посмотреть здесь – https://technet.microsoft.com/en-us/library/ms.exch.scom.ecp(v=exchg.150).aspx (Troubleshooting ECP Health Set).
Наборы здоровья дальше объединяются в функциональные единицы, которые называются группами здоровья (Health Groups). Существует четыре группы, которые отображаются на портале OpsMgr:
- Customer Touch Points – компоненты, с которыми пользователь взаимодействует напрямую (например, OWA).
- Service Components – компоненты, с которыми пользователь напрямую не взаимодействует (например, OAB generation).
- Server Components – физические ресурсы сервера (например, диск, оперативная память).
- Dependency Availability – внешние к системе Exchange компоненты (например, Active Directory).
Интересные ссылки:
Lessons from the Datacenter: Managed Availability
Managed Availability and Server Health
Managed Availability Probes
Managed Availability Monitors
Managed Availability Responders
Customizing Managed Availability
What Did Managed Availability Just Do To This Service?
Exchange 2013 Management Pack Health Sets
Managed Availability
UC². Встреча №10. Мониторинг Exchange Server
Огонь! Спасибо, очень познавательно!